Apple Trailers just begs to be eye tracked.
Two weeks ago, we started an eye-tracking study of Apple’s iTunes movie trailers site. Originally, we had hoped to do a demographic breakdown of the study results — what posters did men like, what posters did women like, that sort of thing. However, the only statistically significant finding we were able to pull out was that people under 30 looked at Harry Potter ads longer than people over 30 — hardly groundbreaking. So we set at analyzing the data from the perspective of the posters themselves.
Does the poster matter at all?
Let’s build a naive model of how people look at the iTunes trailer site: assume that the content of the poster doesn’t matter, and that when moving from the top of the site to the bottom, people randomly decide to look at one of the 2-3 posters immediately below the one they’re currently staring at. Further assume that 15% of the time, people get bored and decide not to move on to the next row.
With just these assumptions, in each row you’d expect a distribution of views that looks like the familiar normal distribution: more eyeballs in the center than by the sides. You’d further expect this distribution to get more normal as you iterate down the rows. And guess what? You’d be right. Using these assumptions, we created a matrix giving the expected number of eyeballs hitting each poster. On average, the difference between the observed number of glances at a poster and the number our model predicted was about 1.7, out of an average of 8.2 glances per poster.
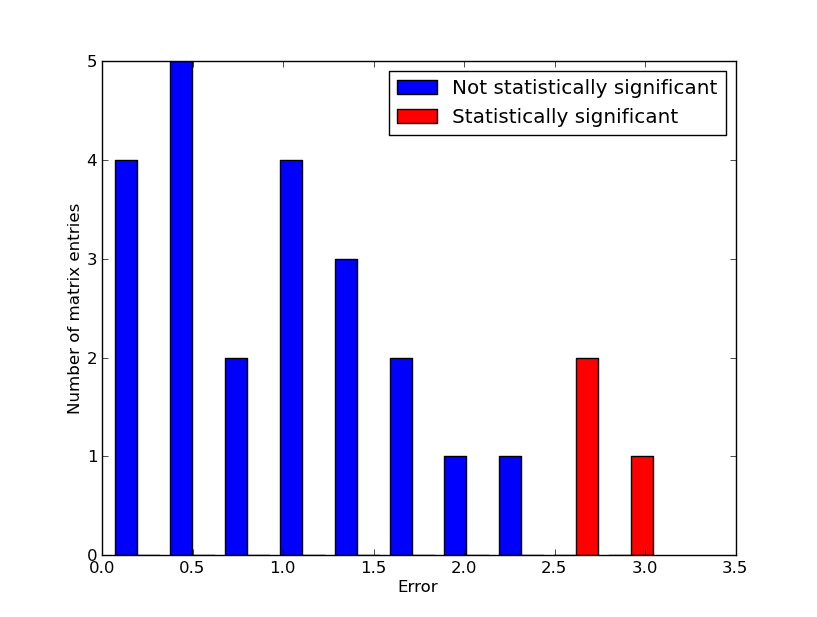
x = |Observed - Predicted|, n = 25
If that didn’t set off bells in your head, let me put it this way: you can assume the content of the posters doesn’t matter and still predict the overall distribution of glances with 80% accuracy. It’s as if the content of the posters doesn’t matter that much; instead their location on the page is almost everything. The location-based model fits, too: if it were systemically wrong, we would expect to see a non-random distribution of error. Instead, as the histogram shows, the error is distributed normally with a few outliers on the edges.

An aggregate heatmap of the whole study. Yes, everyone loves the big Harry Potter ad, but notice how little attention the far left side got.
Exceptions exist, but are hard to explain
So what were these outliers? From a movie studio’s perspective, two were good: both Cowboys and Aliens and Kidnapped received significantly more views than expected, while Viva Riva! received significantly less. (Note that with 30 cells, at 95% confidence for statistical significance we expect one or two cells to be significant just by random chance.) It really isn’t clear why these posters varied so much from the others — this is exactly the sort of situation where explanations are easy to invent but hard to prove. I initially thought the simple silver-on-black scheme of Kidnapped’s poster drew a lot of attention because it provided people with a safe haven from the color and contrast of all the other posters. But this theory isn’t predictive: if it worked for Kidnapped, why didn’t it work for Pariah?
Moreover, it’s possible that the features that attract eyeballs to a particular poster are intensely context-dependent; a black poster like Kidnapped might attract attention when placed next to a colorful thing like Green Lantern, but not when paired with something grey like X-Men: First Class. We’d need to duplicate this study on randomized arrangements of the posters to get a good feel for this sort of thing.
So, how do people look at the Apple Trailers site? For the most part, randomly. They bounce around like pinballs in a Pachinko board, without any sense of direction or apparent purpose. In that situation, it’s incredibly difficult to reliably attract attention from your readers. If there’s a lesson to be learned from this study, that’s it: if you want to get your readers to look at something, don’t confuse them.
Or you could say Apple has accomplished making a perfectly balanced browsable space with two features slots. Each poster is of equal density and size, and users browse them with equal emphasis. Its a great way to emulate the browser experience we enjoy so much at the store. It allows us to search with our eyes again, rather than be directed violently by control freak designers.
You are assuming that Apple placed the posters randomly.
So for example that Apple purposely placed the more popular posters on the fringes to counter the center bias that you describe. If they did so, your study simply proves that they did a good job of it.
Redo the tests, randomly placing the posters each time.
We did consider this possibility. We intend to run larger studies with more statistical significance in the future: this was an unexpected realization from running the Apple study that we thought was interesting enough to share.
No one looks at Hermione.
I wonder if the results would have been any different if the website were in grayscale instead of color. Also, did users end up clicking on the movies they looked at the most? I use Netflix a lot and I noticed that when I didn’t want to watch any particular movie, I’d just randomly look/click around until I found one that seemed interesting enough
I’ve actually stopped using the website. I found it extremely annoying when trying to watch the Harry Potter trailer when the full screen option was withdrawn. I went to Youtube instead. Apple should stop supporting these god awful custom movie landing pages.